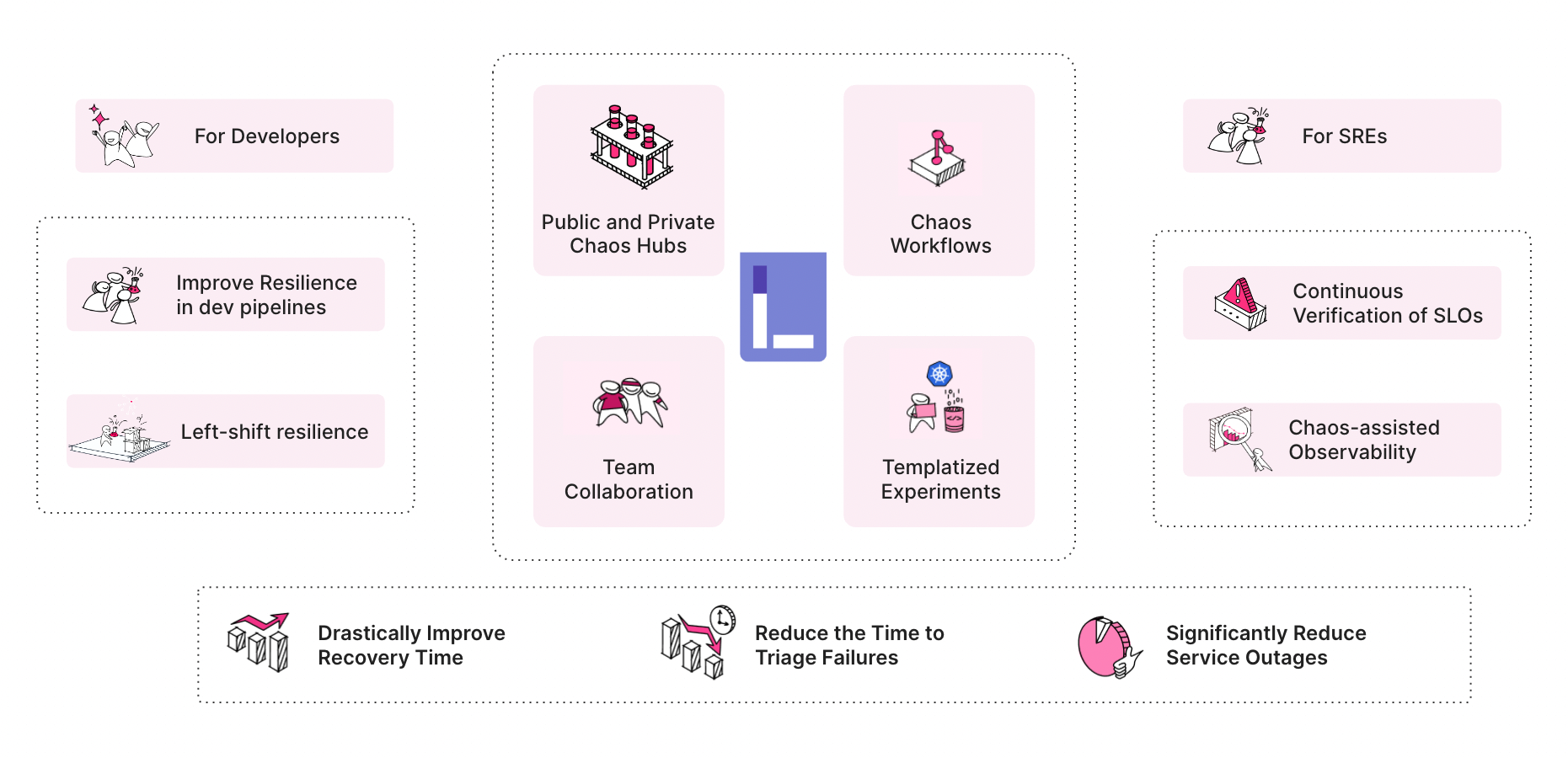
Uses of Litmus
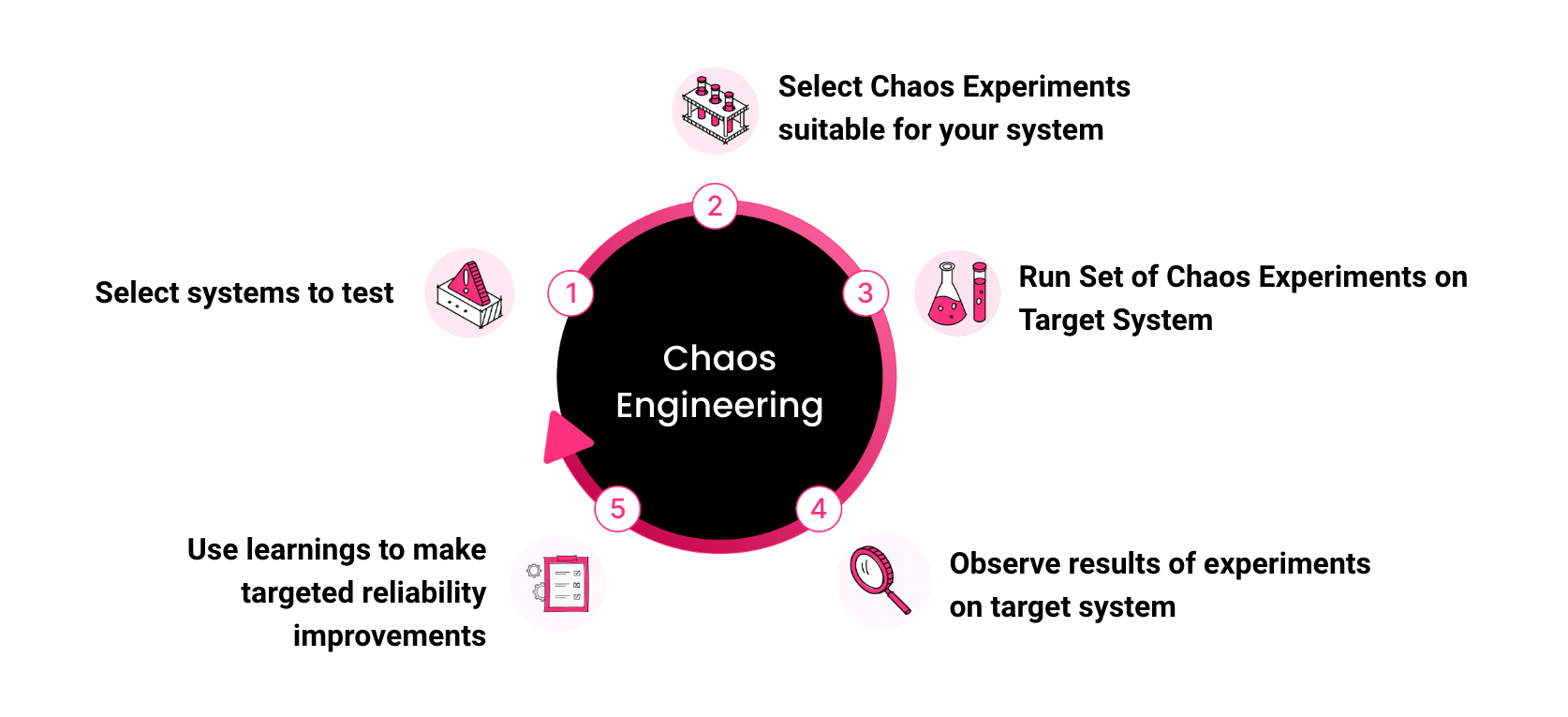
Chaos experiments can be done anywhere in the DevOps cycle. The extent of chaos tests varies from CI pipelines to production. In development pipelines, you might use chaos tests specific to applications being developed. As you move towards operations or production, you will expect a lot of failure scenarios for which you want to be resilient against, hence the number of chaos tests grows significantly.
Common Use Cases
Typical use cases of Litmus include – failure or chaos testing in CI pipelines, increased chaos testing in staging and production and production environments, Kubernetes upgrades certification, post-upgrade validation of services, and resilience benchmarking, etc.
- For Developers: To run chaos experiments during application development as an extension of unit testing or integration testing.
- For CI pipeline builders: To run chaos as a pipeline stage to find bugs when the application is subjected to fail paths in a pipeline.
- For SREs: To plan and schedule chaos experiments into the application and/or surrounding infrastructure. This practice identifies the weaknesses in the system and increases resilience.
We keep hearing from SREs that they typically see a lot of resistance for introducing chaos from both developers and management. In the practice of chaos engineering, starting with small chaos tests and showing the benefits to developers and management will result in the initially required credibility. With time, the number of tests and associated resilience also will increase.
Chaos Engineering is a culture-oriented practice. With time, management buying and the SRE confidence will increase, and they move the chaos tests into production. This process will increase resilience metrics, as well.